Motivation
In this blog, we will reimplement Redpanda's iobuf library as introduced in their blog post.
The full source code is available here.
To understand iobuf, we need to first understand Redpanda's threading and memory model. Redpanda uses a thread-per-core (TpC) architecture. TpC is a programming model that addresses the two shortcomings of threaded programming:
- Threads executing on the same data require synchronization mechanisms like locks, which are expensive.
- Context switching is required when a thread suspends itself and lets another thread run. Context switching is expensive.
In TpC, each application thread is pinned to a CPU. Since the OS cannot move the threads around, there are no context switches. Furthermore, under TpC each thread relies on message passing instead of shared memory to share data. This eliminates synchronization overheads from locks. To learn more about TpC, check out this article by Seastar or this blog by Glommio.
Under Seastar, Redpanda's TpC framework, the full memory of the computer is split evenly across the cores during system bootup. As stated in Redpanda's blog, "memory allocated on core-0 [core-N], must be deallocated on core-0 [core-N]. However, there is no way to guarantee that a Java or Go client connecting to Redpanda will communicate with the exact core that owns the data". Therefore, Redpanda created iobuf, "a ref-counted, fragmented-buffer-chain with deferred deletes that allows Redpanda to simply share a view of a remote core’s parsed messages as the fragments come in, without incurring a copy overhead". In other words, iobuf is a way for Redpanda to share data across cores cheaply and deallocate the data in the core that owns the data when no cores need that data.
Now, let's look at how it works under the hood by examining my toy implementation!
Temporary Buffer
Before we implement the iobuf, we need to first implement its building block, the Temporary Buffer.
Temporary Buffer is a memory management abstraction for a contiguous region of memory. What makes temporary buffers different from buffers like Vec is that the underlying memory can be shared with another temporary_buffer. In other words, it is a buffer with an automatic reference count, kind of like an Arc in Rust.
My implementation is largely inspired by Seastar’s implementation.
API
Constructor
To create a TemporaryBuffer, you use the new: (size: usize) -> TemporaryBuffer API.
#![allow(unused)] fn main() { let buffer = TemporaryBuffer::new(12); }
Write
To write into a TemporaryBuffer, you call get_write(&self) -> Option<*mut u8>. It is dangerous to return a mutable raw pointer if there is another reference to the TemporaryBuffer as the other buffer may not expect data to change. Therefore, get_write would return None if there are more than one reference to the buffer.
#![allow(unused)] fn main() { let buffer = TemporaryBuffer::new(12); let ptr = buffer.get_write().unwrap(); let data: Vec<u8> = vec![1, 2, 3]; unsafe { std::ptr::copy_nonoverlapping(data.as_ptr(), ptr, 3); } }
Share
To share a buffer, you can either use share(&self) -> TemporaryBuffer to share the entire buffer or share_slice(&self, pos: usize, len: usize) -> TemporaryBuffer to get a sliced reference to the temporary buffer.
Note that in either scenario, the underlying data will not be destroyed until all references to the buffer is destroyed. This means that having a tiny slice of a temporary buffer would result in the entire data the original temporary buffer holds to be held in memory.
#![allow(unused)] fn main() { let buffer = TemporaryBuffer::new(12); { let second = buffer.share(); assert_eq!(buffer.get_ref_count(), 2); { let slice = buffer.share_slice(0, 3); assert_eq!(buffer.get_ref_count(), 3); } } assert_eq!(buffer.get_ref_count(), 1); }
In the example above, we created multiple references to the buffer in different scopes. In the deepest scope, the reference count for the buffer is 3. But in the outmost scope, since the scoped references get dropped, there is only 1 ref count.
Internals
Conceptually, a temporary_buffer is quite similar to an Arc. Instead of Arc::clone, you perform share or share_slice to increment the ref count. When the reference count reaches 0, the underlying data is deallocated.
#![allow(unused)] fn main() { pub struct TemporaryBuffer { deleter: NonNull<BufferInternal>, size: usize, buffer: *mut u8, } struct BufferInternal { ref_counter: AtomicUsize, size: usize, buffer: *mut u8, } }
This is what the TemporaryBuffer looks like under the hood:
Each TemporaryBuffer has a NonNull raw pointer to a BufferInternal. BufferInternal keeps track of the reference counts and deallocates the memory when the reference count reaches 0.
This is the implementation for the constructor:
#![allow(unused)] fn main() { pub fn new(size: usize) -> Self { let layout = Layout::array::<u8>(size).unwrap(); let buffer = unsafe { alloc(layout) }; TemporaryBuffer { deleter: NonNull::from(Box::leak(Box::new(BufferInternal { ref_counter: AtomicUsize::new(1), size, buffer, }))), size, buffer, } } }
Here, we used Box::new to create a new allocation and Box::leak to give up ownership of the value without deallocating the memory associated with it. Then we use NonNull to get the pointer to the memory.
This is the implementation of share_slice. Each time it’s called, the deleter's ref_count is incremented by one. We can use Relaxed memory ordering here because
#![allow(unused)] fn main() { pub fn share_slice(&self, pos: usize, len: usize) -> TemporaryBuffer { if self.get_deleter().ref_count.fetch_add(1, Relaxed) > usize::MAX / 2 { std::process::abort(); } TemporaryBuffer { deleter: self.deleter, size: len, buffer: unsafe { self.buffer.add(pos) }, } } }
Just as we increment the ref count when sharing the buffer, we decrement the ref count (with fetch_sub when the buffer gets dropped (i.e. out of scope).
#![allow(unused)] fn main() { impl Drop for TemporaryBuffer { fn drop(&mut self) { if self.get_deleter().ref_count.fetch_sub(1, Release) == 1 { fence(Acquire); unsafe { let layout = Layout::array::<u8>(self.deleter.as_ref().size).unwrap(); dealloc(self.deleter.as_ref().buffer, layout); drop(Box::from_raw(self.deleter.as_ptr())); } } } } }
If fetch_sub returns 1, we need to ensure that no other references have access to the underlying memory. Note that this isn’t trivial as the buffer is not part of the atomic ref_count. To guarantee that any non-atomic loads and stores to buffer occur before the final fetch_sub, we need to establish a happens-before relationship between the final fetch_sub and all other fetch_subs.
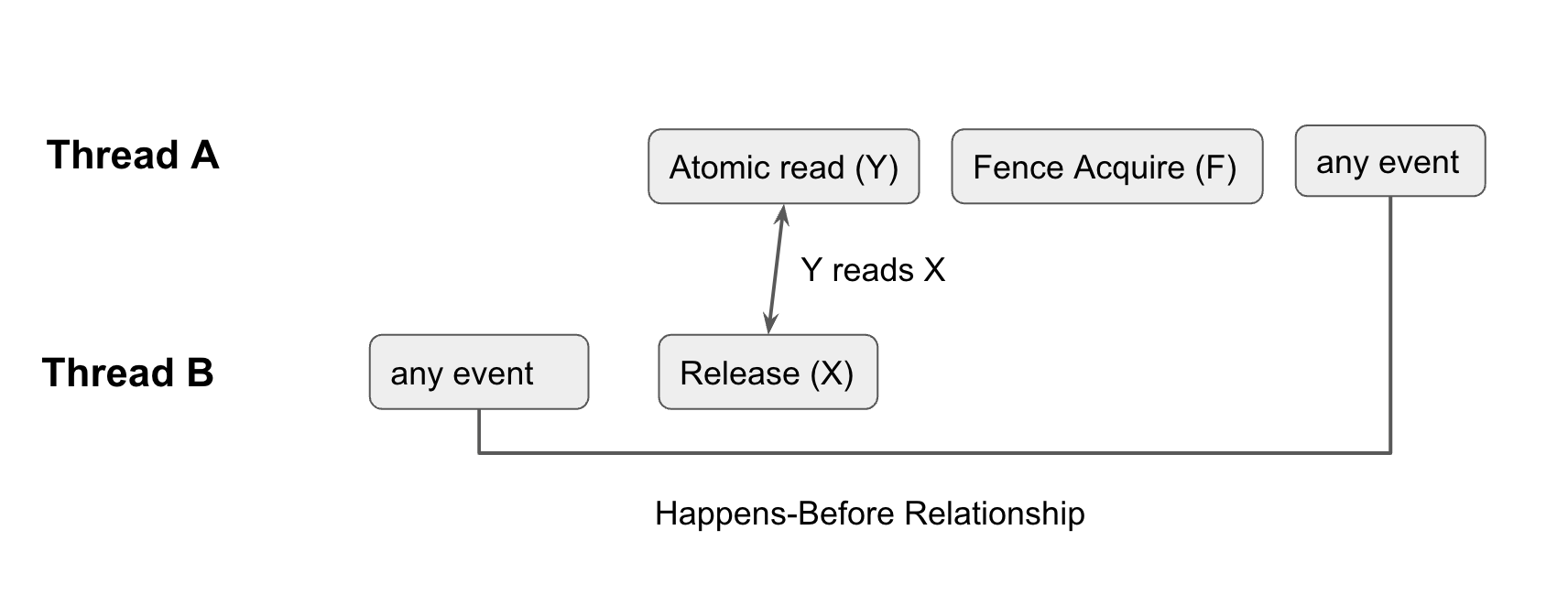
The figure above illustrates how we establish the happens-before relationship. Note that all atomic operations (even relaxed ones) have total modification order for that atomic variable. This means that all modifications of the same atomic variable happen in an order that is the same from the perspective of every single thread. This means that if fetch_sub returns 1, it is the last fetch_sub.
We use an acquire fence to guarantee that whatever happens after the fence happens after any event before all other final_subs. Since loads or modifications to the buffer count as any event, we guarantee that after the fence, no other threads have access to the underlying memory.
Check out the implementation on github here.
IoBuf
My toy iobuf implementation is based on Redpanda's iobuf implementation.
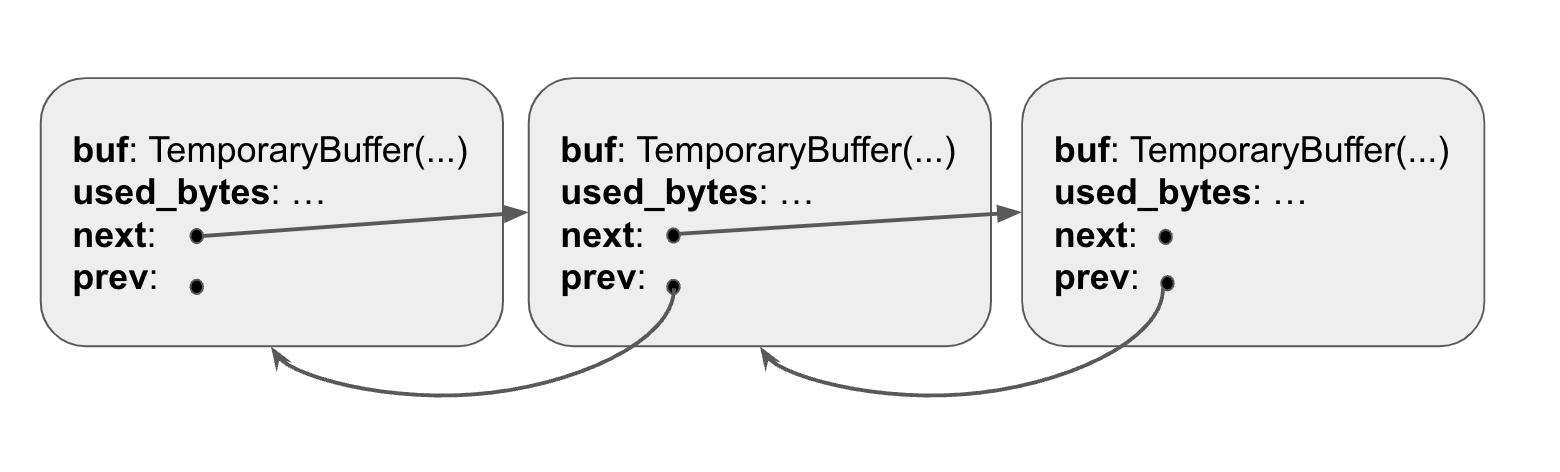
Iobuf is pretty much just a linked list of TemporaryBuffers. Each Temporary Buffer is wrapped around an IoFragment, which is like a linked list node with next/prev pointers to other fragments.
API
Constructor
There are a few different ways to create an iobuf. The easiest way is to just use the new() -> Iobuf as follows:
#![allow(unused)] fn main() { let mut iobuf = IoBuf::new(); }
Append
There are a few different ways to append data to an iobuf. Here are some of the method signatures to append:
#![allow(unused)] fn main() { fn append(&mut self, src: *const u8, len: usize) -> (); fn append_temporary_buffer(&mut self, buffer: TemporaryBuffer); fn append_fragment(&mut self, fragment: IoFragment); }
Iterator
To create an iterator over the IoFragments that make up the iobuf, you can call the begin() method with the signature: fn begin<'a>(&'a self) -> IoFragmentIter<'a>.
I’ll go deeper into iterators in the next page where I talk about IoIteratorConsumer.
Internals
#![allow(unused)] fn main() { pub struct IoBuf { frags: LinkedList<IoFragmentAdapter>, // number of bytes the IoBuf contains size: usize, } }
As we can see from the definition of IoBuf, it’s pretty much just a linked list of IoFragment nodes. The IoBuf itself doesn’t store any data, it just holds pointers to temporary buffer instances, which actually hold the data.
Similar to Redpanda’s implementation, I also used an intrusive linked list from the intrusive_collections trait.
The main difference between an intrusive collection and a normal collection is that intrusive collections don’t allocate memory themselves. This means that the next and prev pointers directly live inside the nodes. Intrusive collections are good because they eliminate dynamic memory allocation, which may cause the memory pools to be fragmented.
To work with the intrusive linked list, I just needed to use the intrusive_adapter macro like this:
#![allow(unused)] fn main() { intrusive_adapter!(pub IoFragmentAdapter = Box<IoFragment>: IoFragment { link: LinkedListLink }); }
The macro automatically creates an IoFragmentAdapter with next and prev pointers. IoFragmentAdapter is the actual linked list node the iobuf uses.
The actual definition of IoFragment is:
#![allow(unused)] fn main() { pub struct IoFragment { used_bytes: RefCell<usize>, buf: TemporaryBuffer, pub link: LinkedListLink, } }
Append
Let’s look at how we implement fn append(&mut self, src: *const u8, len: usize) -> ();
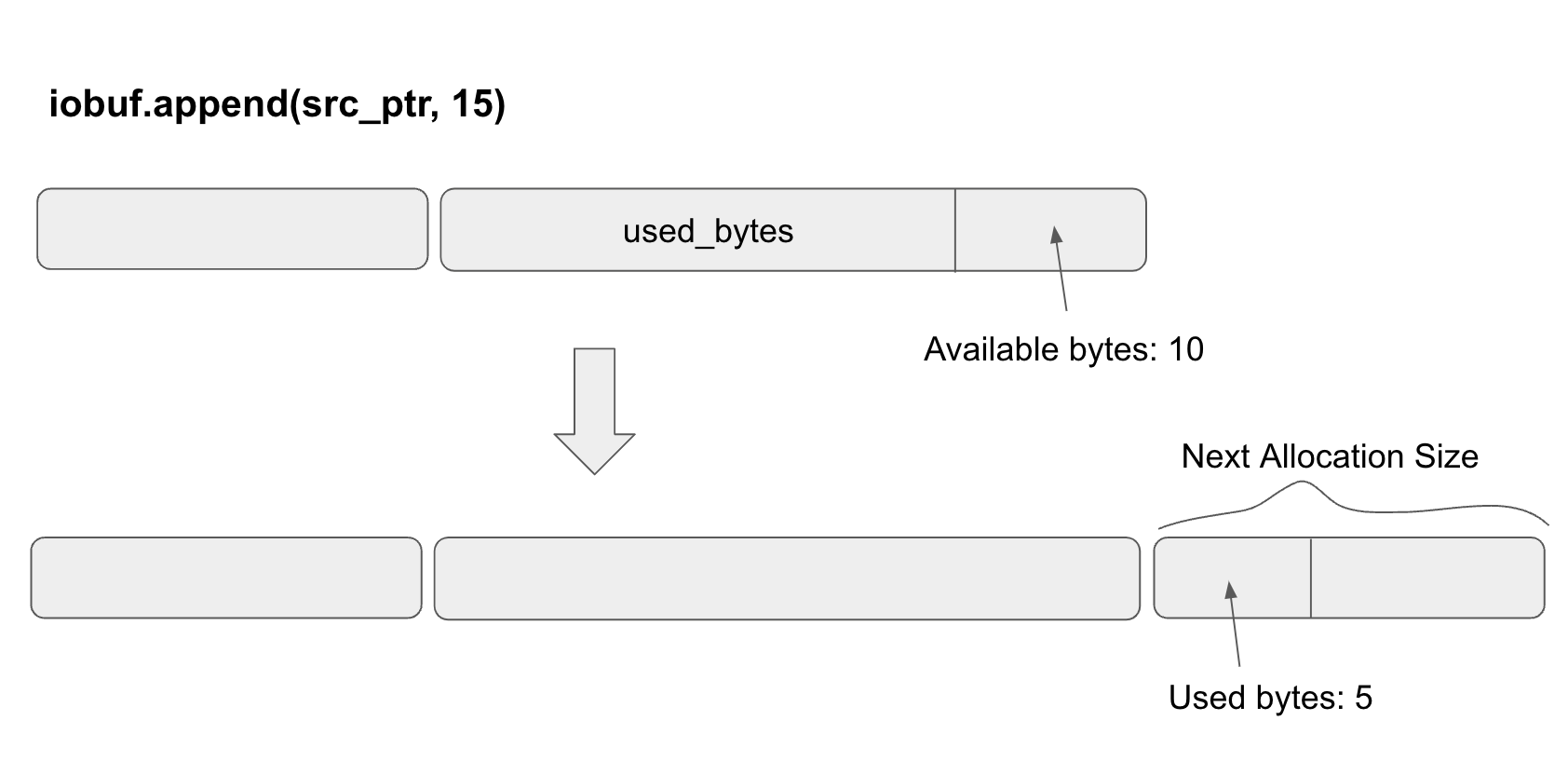
The diagram shows an iobuf with 2 fragments. The second fragment has 10 available bytes. If we insert 15 bytes into the iobuf, it will first fill in the available bytes. Then it will create a new io_fragment with the next allocation size and fill the remaining 5 bytes into the next fragment.
Computing the next allocation size is based on the iobuf allocation table logic provided by Redpanda. In general, fixed sizing and size capping help reduce memory fragmentation.
Here is the implementation of append:
#![allow(unused)] fn main() { pub fn append(&mut self, src: *const u8, len: usize) -> () { if len <= self.available_bytes() { let fragment = self.get_last_fragment(); self.size += fragment.append(src, len); return; } let mut remaining = len; let mut ptr = src; while remaining > 0 { self.append_new_fragment(remaining); let appended_size = self.get_last_fragment().append(ptr, remaining); ptr = unsafe { ptr.add(appended_size) }; remaining -= appended_size; self.size += appended_size; } } }
Share
Sharing an iobuf based on a pos and a len simply creates a new iobuf and find the io_fragments that intersect with the share range. If it is, we use the temporary_buffer's share method to get a reference of the temporary buffer.
#![allow(unused)] fn main() { pub fn share(&self, pos: usize, len: usize) -> IoBuf { let mut ret = IoBuf::new(); let mut remaining = len; let mut pos = pos; for fragment in self.frags.iter() { if remaining == 0 { return ret; } if pos >= fragment.size() { pos -= fragment.size(); continue; } let right = std::cmp::min(pos + remaining, fragment.size() - 1); let buffer = fragment.share(pos, right); ret.append_temporary_buffer(buffer); remaining -= right - pos - 1; } ret } }
In other words, share increments the reference count of each of the temporary buffers that it intersects. When the iobuf drops, all the reference counts of the temporary buffers drop. Each temporary buffer is responsible for deallocating the memory if the reference count reaches zero.
Check out the implementation of iobuf here.
IoIteratorConsumer
To get data out of an iobuf, the best way is to use a consumer iterator. My IoIteratorConsumer implementation is based on Redpanda’s implementation. Check out their source code here.
#![allow(unused)] fn main() { let mut iobuf = IoBuf::new(); let values1 = generate_random_u8_vec(1000); iobuf.append(values1.as_ptr(), values1.len()); let values2 = generate_random_u8_vec(3000); iobuf.append(values2.as_ptr(), values2.len()); let mut consumer = IoIteratorConsumer::new(iobuf.begin()); let arr = consumer.consume_to_arr(1000); assert_eq!(values1, arr); let arr2 = consumer.consume_to_arr(3000); assert_eq!(values2, arr2); }
This example showcases how the IoIteratorConsumer is used. You initialize it with a pointer to an IoFragmentIter. You then invoke consumer_to_arr to copy the data into an array. Note that each call to consume_to_arr would advance the iterator pointer under the hood.
The method consume_to_arr is actually powered by the consume method, which takes a callback with the start pointer and the size.
#![allow(unused)] fn main() { pub fn consume<T>(&mut self, n: usize, consumer: T) where T: Fn(*const u8, usize) -> (), { let mut consumed = 0; while self.current_frag.is_some() && consumed < n { let segment_bytes_left = self.segment_bytes_left(); if segment_bytes_left == 0 { self.current_frag = self.frag_it.next(); self.frag_index = self.current_frag.map(|frag| frag.get_start()); continue; } let step = std::cmp::min(segment_bytes_left, n - consumed); let frag_index = self.frag_index.unwrap(); consumer(frag_index, step); self.frag_index = Some(unsafe { frag_index.add(step) }); consumed += step; } } }
The algorithm iterates over the fragments and calls callbacks with the start pointer and the size of that fragment to consume. Once the number of elements that have been consumed reaches n, the iterator stops.