Motivation
I've always wondered how asynchronous runtimes like Node.js, Seastar, Glommio, and Tokio work under the hood. Luckily, most asynchronous runtimes are open source. There is also a bunch of excellent blogs online such as the Asychronous Programming in Rust blog series.
To better understand the internals of asynchronous runtimes, I built mini-async-runtime, a lightweight, toy asynchronous runtime written in Rust. I reused a lot of code from Glommio and async-io to help myself prototype faster, since my goal was just to gain a better intuition for how these systems really work. The source code is available online.
In this blog series, I will deep dive into the internals of mini-async-runtime. Even though my implementation is in Rust, this blog is meant to
be language agnostic as most asynchronous runtimes, even in other languages, use a similar event-loop + reactor architecture.
What is an asynchronous runtime?
Synchronous programming is a programming paradigm in which each line of code executes sequentially, one after the other. In contrary, asynchronous programming allows multiple tasks to run in parallel through simple primitives such as async/await and futures (or Promises in Javascript).
One way that a developer can achieve multitasking without an asynchronous runtime is to use multithreading - just spawn a thread for each task. However, creating a new thread for each task will introduce a bunch of overhead to the system. Each CPU core can only run a task at any given moment. So the OS will start performing expensive context switches between the threads as the number of threads grow. Also, imagine if you are building a server that can serve millions of request per second. Creating a new thread for each connection will overwhelm the system quickly.
Furthermore, look at how much simpler it is to write concurrent program like the one below as opposed to having to manually create a thread for each task:
async function f() {
const promiseOne = writeToFile()
const promiseTwo = writeToExternalServer()
await Promise.all([promise1, promise2, promise3])
}
In this example, the two I/O calls are run in parallel. The function will then wait until the two calls complete before exiting.
In other words, an asynchronous runtime is a library that enables multitasking without creating a new thread for each task. It multiplexes multiple tasks onto a single thread or a thread pool, depending on the implementation.
What are we building?
I’ve split up the blog series into four phases:
- Phase 1: In phase 1, we will build an executor. We will first cover Rust’s asynchronous primitives like
Future,Async/Await, andWakerwhich will serve as building blocks for the asynchronous runtime. - Phase 2: In phase 2, we talk about
io_uringand use it to addasynchronous I/Oto our executor - Phase 3 [WIP]: In phase 3, we will implement more advanced features such as thread parking, task yielding, and scheduling tasks based on priority.
- Phase 4 [WIP]: In phase 4, we will build more advanced abstractions such as Executor Pools.
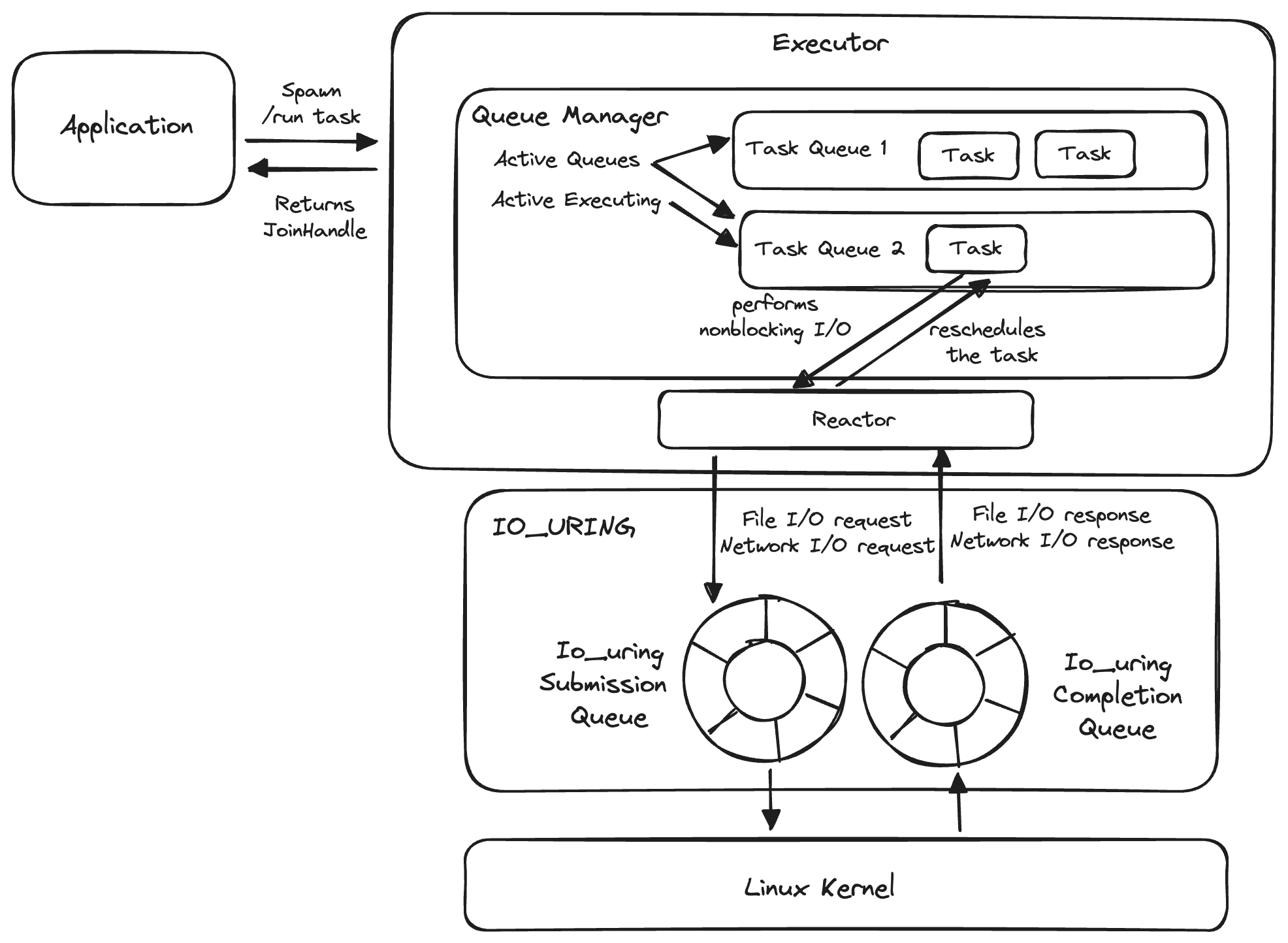
As a teaser, here is the architecture of the async runtime that we are building:
What is an executor?
As we mentioned earlier, asynchronous programming allows multiple tasks to run on a single thread (or a thread pool). To do that, we need a scheduler that figures out which task to run at any moment and when to switch tasks. That is what an executor does.
There are two categories for how an executor schedules task:
- In preemptive multitasking, the executor decides when to switch between tasks. It may have an internal timer that forces a task to give up control to the CPU to ensure that each task gets a fair share of the CPU.
- In cooperative multitasking, the executor lets the task run until it voluntarily gives up control back to the scheduler.
In this section, we will build an executor that performs cooperative multitasking. Through that, we will answer the following questions:
- How is a task represented?
- How are the tasks stored in an executor?
- How does a task "give up control" back to the scheduler?
Now, let's look at the API of the executor.
API
Each asynchronous runtime needs an executor to manage tasks. Most asynchronous runtimes implicitly create an executor for you.
For example, in Tokio an executor is created implicitly through #[tokio::main].
#[tokio::main]
async fn main() {
println!("Hello world");
}
Under the hood, the annotation actually creates the excutor with something like:
fn main() {
tokio::runtime::Builder::new_multi_thread()
.enable_all()
.build()
.unwrap()
.block_on(async {
println!("Hello world");
})
}
In Node.js, the entire application runs on a single event loop. The event loop is initialized when the node command is run.
In Tokio and Node.js, the developer can write asynchronous code without ever knowing the existence of the executor. With mini-glommio, developers need to create the executor explicitly.
The two main APIs of our executor are:
- run: spawns a task onto the executor and wait until it completes
- spawn: spawns a task onto the executor
Pretty simple right? All we need is the ability to put a task onto the executor and to run the task until completion.
Run
To run a task, you call the run method, which is a synchronous method and runs the task until completion.
Here is its signature:
#![allow(unused)] fn main() { pub fn run<T>(&self, future: impl Future<Output = T>) -> T }
Here is a simple example of using the APIs to run a simple task that performs arithmetics:
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); let res = local_ex.run(async { 1 + 2 }); assert_eq!(res, 3) }
spawn
The whole point of an asynchronous runtime is to perform multitasking. The spawn method
allows the programmer to spawn a task onto the executor without waiting for it to complete.
#![allow(unused)] fn main() { pub(crate) fn spawn<T>(&self, future: impl Future<Output = T>) -> JoinHandle<T> }
The spawn method returns a JoinHandle which is a future that returns the output of the task
when it completes.
Note that the spawn method can technically be run outside a run block. However, that means
the programmer would need to manually poll the JoinHandle to wait until it completes or use another
executor to poll the JoinHandle.
Running spawn inside the run block allows the programmer to just await the JoinHandle.
Here is an example for how to use spawn.
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); let res = local_ex.run(async { let first = local_ex.spawn(async_fetch_value()); let second = local_ex.spawn(async_fetch_value_2()); first.await.unwrap() + second.await.unwrap() }); }
spawn_local_into
This is a more advanced API that gives a developer more control over the priority of tasks. Instead of placing all the tasks onto a single TaskQueue (which is just a collection of tasks), we can instead create different task queues and place each task into one of the queues.
The developer can then set configurations that control how much CPU share each task queue gets.
To create a task queue and spawn a task onto that queue, we can invoke the spawn_into method as follows:
#![allow(unused)] fn main() { local_ex.run(async { let task_queue_handle = executor().create_task_queue(...); let task = local_ex.spawn_into(async { write_file().await }, task_queue_handle); } ) }
Next, I will cover the Rust primitives that our executor uses - Future, Async/Await, and Waker. Feel free to skip if you are already familiar with these. However, if you are not familiar with them, even if you aren't interested in Rust, I strongly advice understanding them as those concepts are crucial in understanding how asynchronous runtimes work under the hood.
Prerequisites - Primitives
If you are already familiar with these primitives, feel free to skip this section. If you want a more thorough explanation of these primitives, I recommend Philipp Oppermann’s Async/Await blog.
Future
A future represents a value that might not be available yet. Each future implements the std::future::Future trait as follows:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; } }
The associated type, Output, represents the type of the output value.
The poll method returns whether the value is ready or not. It’s also used to advance the Future towards completion. The poll method returns Poll::Ready(value) if it’s completed and Poll::Pending if it’s not complete yet. It’s important to understand that a Future does nothing until it’s polled. Polling a future forces it to make progress.
The Poll enum looks like this:
#![allow(unused)] fn main() { pub enum Poll<T> { Ready(T), Pending, } }
The poll method takes in a Context argument. As we will cover soon, the Context holds a Waker instance which notifies any interested tasks that are blocked by the current task.
Async/Await
Async/Await is syntactic sugar for building state machines. Any code wrapped around the async block becomes a future.
This allows the programmer to begin a task without waiting for it to complete. Only when the future is awaited does the task block the execution.
During compilation, the compiler turns code wrapped in the async keyword into a pollable state machine.
As a simple example, let's look at the following async function f:
#![allow(unused)] fn main() { async fn f() -> u32 { 1 } }
The compiler may compile f to something like:
fn compiled_f() -> impl Future<Output = u32> {
future::ready(1)
}
Let's look at a more complex example:
#![allow(unused)] fn main() { async fn notify_user(user_id: u32) { let user = async_fetch_user(user_id).await; if user.group == 1 { async_send_email(&user).await; } } }
The function above first fetches the user's data, and conditionally sends an email to that user.
If we think about the function as a state machine, here are its possible states:
- Unpolled: the start state of the function
- FetchingUser: the state when the function is waiting for
async_fetch_user(user_id)to complete - SendingEmail: the state when the function is waiting for
async_send_email(user)to complete - Ready: the end state of the function.
Each point represents a pausing point in the function. The state machine we are going to create implements the Future trait. Each call to the future’s poll method performs a possible state transition.
The compiler creates the following enum to track the state of the state machine (note that my examples are for demonstration purposes and not what the compiler actually generates)
#![allow(unused)] fn main() { enum State { Unpolled, FetchingUser, SendingEmail, Ready } }
Next, the compiler generates the following struct to hold all the variables the state machine needs.
#![allow(unused)] fn main() { struct NotifyUser { state: State, user_id: u32, fetch_user_fut: Option<impl Future<Output = User>>, send_email_fut: Option<impl Future<Output = ()>>, user: Option<User> } }
To track the progress of async_fetch_user(user_id).await and async_send_email(&user).await, the state machine stores the async_fetch_user's state machine inside the fetch_user_fut field and stores the async_send_email's state machine inside the send_email_fut field.
Note that fetch_user_fut and send_email_fut are both Options. This is because the state machine won’t be initiated until the NotifyUser state machine reaches there. In the case of send_email_fut, the state machine may never be initiated in the case that [user.group](<http://user.group>) is not 1.
Conceptually, fetch_user_fut and send_email_fut are like children state machines that make up a bigger state machine that is the NotifyUser.
Now that we have a state machine, let’s implement the Future trait:
#![allow(unused)] fn main() { impl Future for NotifyUser { type Output = (); fn poll(&mut self, cx: &mut Context) -> Poll<()> { loop { match self.state { State::Unpolled => { todo!() }, State::FetchingUser => { todo!() }, State::SendingEmail => { todo!() }, State::Ready => { todo!() }; } } } } }
The poll method starts a loop because in the case that one of the states isn’t blocked, the state machine can perform multiple state transitions in a single poll call. This reduces the number of poll calls the executor needs to make.
Now, let’s look at how each state performs the state transition.
When we initialize NotifyUser, its state is State::Unpolled, which represents the starting state. When we poll NotifyUser for the first time, it calls async_fetch_user to instantiate and store the fetch_user_fut state machine.
It then transitions its state to State::FetchingUser. Note that this code block doesn’t return Poll::Pending. This is because none of the executed code is blocking, so we can go ahead and execute the handle for the next state transition.
#![allow(unused)] fn main() { State::Unpolled => { self.fetch_user_fut = Some(async_fetch_user(self.user_id)); self.state = State::FetchingUser; } }
When we get to the FetchinUser state, it polls the fetch_user_fut to see if it’s ready. If it’s Pending, we return Poll::Pending. Otherwise, NotifyUser can perform its next state transition. If self.user.group == 1, it needs to create and store the fetch_user_fut state machine and transition the state to State::SendingEmail. Otherwise, it can transition its state to State::Ready.
#![allow(unused)] fn main() { State::FetchingUser => { match self.fetch_user_fut.unwrap().poll(cx) { Poll::Pending => return Poll::Pending, Poll::Ready(user) => { self.user = Some(user); if self.user.group == 1 { self.fetch_user_fut = Some(async_send_email(&self.user)); self.state = State::SendingEmail; } else { self.state = State::Ready; } } } } }
If the state is SendingEmail, it polls send_email_fut to check if it’s ready. If it is, it transitions the state to State::Ready. Otherwise, it returns Poll::Pending.
#![allow(unused)] fn main() { State::SendingEmail => { match self.send_email_fut.unwrap().poll(cx) { Poll::Pending => return Poll::Pending, Poll::Ready(()) => { self.state = State::Ready; } } } }
Finally, if the state is Ready, NotifyUser returns Poll::Ready(()) to indicate that the state machine is complete.
#![allow(unused)] fn main() { State::Ready => return Poll::Ready(()); }
Here is the full code:
#![allow(unused)] fn main() { enum State { Unpolled, FetchingUser, SendingEmail, Ready } struct NotifyUser { state: State, user_id: u32, fetch_user_fut: Option<impl Future<Output = User>>, send_email_fut: Option<impl Future<Output = ()>>, user: Option<User> } impl Future for NotifyUser { type Output = (); fn poll(&mut self, cx: &mut Context) -> Poll<()> { loop { match self.state { State::Unpolled => { self.fetch_user_fut = Some(async_fetch_user(self.user_id)); self.state = State::FetchingUser; }, State::FetchingUser => { match self.fetch_user_fut.unwrap().poll(cx) { Poll::Pending => return Poll::Pending, Poll::Ready(user) => { self.user = Some(user); if self.user.group == 1 { self.fetch_user_fut = Some(async_send_email(&self.user)); self.state = State::SendingEmail; } else { self.state = State::Ready; } } } }, State::SendingEmail => { match self.send_email_fut.unwrap().poll(cx) { Poll::Pending => return Poll::Pending, Poll::Ready(()) => { self.state = State::Ready; } } }, State::Ready => return Poll::Ready(()); } } } } }
Waker
When the executor polls a future, it returns Poll::Pending if it's blocked by another operation, i.e. waiting for the kernel to finish
reading from disk. The question is when should the executor poll again?
A dumb solution is to have the executor periodically poll the Future to check if it's ready yet. But that’s inefficient and wastes CPU cycles.
Instead, a more efficient solution is to pass a callback to the Future and have the Future invoke the callback when it is unblocked. This is what the Waker is for.
The Waker is passed to the Future each time it's polled. As a refresher, here is the function signature for poll:
#![allow(unused)] fn main() { fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> }
Each Context struct contains a waker that can be retrieved with cx.waker(). Each waker has a wake() method, which notifies the executor that the Future is ready to be polled again.
To create a Waker, we can use the from_raw constructor:
#![allow(unused)] fn main() { pub const unsafe fn from_raw(waker: RawWaker) -> Waker }
Each waker has a wake method that can be called when it is done.
Here is an example borrowed from the async book that implements a timer with the waker:
pub struct TimerFuture {
shared_state: Arc<Mutex<SharedState>>,
}
struct SharedState {
completed: bool,
waker: Option<Waker>,
}
impl Future for TimerFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
let mut shared_state = self.shared_state.lock().unwrap();
if shared_state.completed {
Poll::Ready(())
} else {
shared_state.waker = Some(cx.waker().clone());
Poll::Pending
}
}
}
impl TimerFuture {
pub fn new(duration: Duration) -> Self {
let shared_state = Arc::new(Mutex::new(SharedState {
completed: false,
waker: None,
}));
// Spawn the new thread
let thread_shared_state = shared_state.clone();
thread::spawn(move || {
thread::sleep(duration);
let mut shared_state = thread_shared_state.lock().unwrap();
shared_state.completed = true;
if let Some(waker) = shared_state.waker.take() {
waker.wake()
}
});
TimerFuture { shared_state }
}
}
In this example, a thread is created when the TimerFuture is created. The thread simply performs thread::sleep which acts as the timer.
When the future is polled, the waker is stored. When the thread::sleep completes, the waker::wake method is called to notify the poller that it can be polled again.
Implementation Details
Architecture
Here is the asynchronous runtime's architecture:

When the programmer spawns a future onto the executor, a task is created and a JoinHandle is returned to the user.
The user can use the JoinHandle to consume the output of the completed task or cancel the task.
The spawned task is placed onto one of the task queues that the executor has. Each task queue holds a queue of tasks. A queue manager decides which task queue to run. In our V1, the queue manager will simply pick an arbitrary task queue to run at any moment.
We will cover asynchronous I/O and io_uring in Phase 2.
Next, let's perform a deep dive into the implementation details.
Task
A task is the executor's internal representation for a unit of work submitted by the programmer.
A task is created when a programmer spawns a task with a future. For example:
let fut = async { 1 + 2 };
local_ex.spawn(fut);
When spawn is called, the executor takes the future and creates a task. The task stores these properties in addition to the future:
- state
- output
- waker
- references
State
There's a couple of additional state that the executor needs to keep
track of:
- SCHEDULED: set if the task is scheduled for running
- RUNNING: running is set when the future is polled.
- COMPLETED: a task is completed when polling the future returns
Poll::Ready. This means that the output is stored inside the task. - CLOSED: if a task is closed, it’s either canceled or the output has been consumed by a JoinHandle. If a task is
CLOSED, the task’sfuturewill never bepolled again so it can be dropped. - HANDLE: set if the JoinHandle still exists.
For a more thorough explanation of the invariants of the state, check out this code snippet.
The state of the task is stored as an u8. Each of the states is stored as a bit. For example, SCHEDULED is 1 << 0 while HANDLE is 1 << 4.
Output
The task needs to store the output of a Task for the application to await.
#![allow(unused)] fn main() { let handle = spawn_local(async { 1 + 2 }); let res = future.await; }
In this example, the Task needs to store the output (which is 3 in this example) to be consumed by an await.
Awaiter (Waker)
When the task is blocked (e.g. it's blocked by an I/O operation), we want the executor to switch to another task.
But when should the task be scheduled to be run by the executor again?
This is what the Waker is for. The executor creates a Waker and passes it to the task each time it polls the task.
The task stores the waker and invokes Waker::wake when it is unblocked. This will place the task back onto the task queue.
The task stores the Waker inside the awaiter property:
pub(crate) awaiter: Option<Waker>
References
The Task needs to be deallocated when there is no more need for it. The Task is no longer needed if it’s canceled or when it’s completed and the output is consumed. The task has a references counter and the task is deallocated once the reference is 0.
Implementation
The raw task is allocated on the heap as follows:
#![allow(unused)] fn main() { pub struct Task { // Pointer to the raw task (allocated on heap) pub raw_task: NonNull<()>, } }
Here is the implementation of RawTask. It uses raw pointers
#![allow(unused)] fn main() { pub(crate) struct RawTask<F, R, S> { /// The task header. pub(crate) header: *const Header, /// The schedule function. pub(crate) schedule: *const S, /// The future. pub(crate) future: *mut F, /// The output of the future. pub(crate) output: *mut R, } }
The Header contains the state, the references, and the awaiter.
#![allow(unused)] fn main() { pub(crate) struct Header { pub(crate) state: u8, pub(crate) executor_id: usize, /// Current reference count of the task. pub(crate) references: AtomicI16, /// The virtual table. pub(crate) vtable: &'static TaskVTable, /// The task that is blocked on the `JoinHandle`. /// /// This waker needs to be woken up once the task completes or is closed. pub(crate) awaiter: Option<Waker>, } }
Both the Glommio crate and the async_task crate use the virtual table to contain pointers to methods necessary for bookkeeping the task. My understanding is that this reduces the runtime overhead, but let me know if there are other reasons why!
Creating a Task
Finally, to create a Task, you invoke the create_task method:
#![allow(unused)] fn main() { pub(crate) fn create_task<F, R, S>( executor_id: usize, future: F, schedule: S, ) -> (Task, JoinHandle<R>) where F: Future<Output = R>, S: Fn(Task), { let raw_task = RawTask::<_, R, S>::allocate(future, schedule, executor_id); let task = Task { raw_task }; let handle = JoinHandle { raw_task, _marker: PhantomData, }; (task, handle) } }
The create_task method takes a schedule function. Usually, the schedule method simply places the task onto
the task queue.
#![allow(unused)] fn main() { let schedule = move |task| { let task_queue = tq.upgrade(); task_queue.local_queue.push(task); }; create_task(executor_id, future, schedule) }
The core of this function is the allocate method which allocates the Task onto the heap:
#![allow(unused)] fn main() { pub(crate) fn allocate(future: F, schedule: S, executor_id: usize) -> NonNull<()> { let task_layout = Self::task_layout(); unsafe { let raw_task = NonNull::new(alloc::alloc(task_layout.layout) as *mut ()).unwrap(); let raw = Self::from_ptr(raw_task.as_ptr()); // Write the header as the first field of the task. (raw.header as *mut Header).write(Header { state: SCHEDULED | HANDLE, executor_id, references: AtomicI16::new(0), vtable: &TaskVTable { schedule: Self::schedule, drop_future: Self::drop_future, get_output: Self::get_output, drop_task: Self::drop_task, destroy: Self::destroy, run: Self::run, }, awaiter: None, }); // Write the schedule function as the third field of the task. (raw.schedule as *mut S).write(schedule); // Write the future as the fourth field of the task. raw.future.write(future); raw_task } } }
Note that the initial state of a Task is SCHEDULED | HANDLE. It’s SCHEDULED because a task is considered to be scheduled whenever its Task reference exists. There’s a HANDLE because the JoinHandle hasn’t dropped yet.
API
The two most important APIs of a Task are schedule and run.
pub(crate) fn schedule(self)
This method schedules the task. It increments the references and calls the schedule method stored in the Task. In the context of an executor, the schedule method pushes itself onto the Task Queue that it was originally spawned into.
pub(crate) fn run(self)
The run method is how the user-provided future gets polled. Since the run method is quite meaty, I will dedicate the entire next page to talk about how it works.
Code References
To check out my toy implementation or Glommio’s implementation, check out:
My Toy Implementation
Glommio
Running the Task
To run the user-provided future, the executor needs to poll the future. This is what the Task::run function does.
However, the task needs to do more than just polling the future. In this page, we will look at all the things the executor needs to do when running a task.
Here is the simplified pseudocode for the run method:
fn run(task) {
if the task is closed:
decrement the reference count
deallocate if reference is 0
poll the user-provided future
if future is ready:
store the output into the task
if there is no handle, then drop the output
notify the awaiter that the task has been completed
else:
if the task was closed while running, unschedule the task.
}
In general, the executor needs to perform the following tasks:
- deallocate the task/task output when necessary
- create the waker that notifies the
executorto reschedule thetaskwhen the future is no longer blocking - track the state of the task and terminate early if the task is cancelled or completed
The actual code is quite complicated. Feel free to skip if you are only interested in the higher level. Let's look at it section by section:
#![allow(unused)] fn main() { unsafe fn run(ptr: *const ()) -> bool { let raw = Self::from_ptr(ptr); let mut state = (*raw.header).state; // Update the task's state before polling its future. // If the task has already been closed, drop the task reference and return. if state & CLOSED != 0 { // Drop the future. Self::drop_future(ptr); // Mark the task as unscheduled. (*(raw.header as *mut Header)).state &= !SCHEDULED; // Notify the awaiter that the future has been dropped. (*(raw.header as *mut Header)).notify(None); // Drop the task reference. Self::drop_task(ptr); return false; } ... } }
First, we check if the task is already closed. If it is, we want to return early. But before returning, we need to unset the SCHEDULED bit of the Task’s state. We also want to notify the awaiter (blocked task) that it is unblocked.
The notify method’s implementation is as follows:
#![allow(unused)] fn main() { /// Notifies the awaiter blocked on this task. pub(crate) fn notify(&mut self, current: Option<&Waker>) { let waker = self.awaiter.take(); // TODO: Check against current if let Some(w) = waker { w.wake() } } }
As mentioned earlier, a task stores the waker. The notify method calls the waker.
If the Task isn’t closed, we can proceed with running the Task. First, we update the state of the Task by unsetting the SCHEDULED bit and setting the RUNNING bit.
#![allow(unused)] fn main() { // Unset the Scheduled bit and set the Running bit state = (state & !SCHEDULED) | RUNNING; (*(raw.header as *mut Header)).state = state; }
Next, we poll the Task’s Future. Polling a future requires a waker. We create one with RAW_WAKER_VTABLE which we will cover in more detail in another page.
#![allow(unused)] fn main() { let waker = ManuallyDrop::new(Waker::from_raw(RawWaker::new(ptr, &Self::RAW_WAKER_VTABLE))); let cx = &mut Context::from_waker(&waker); let poll = <F as Future>::poll(Pin::new_unchecked(&mut *raw.future), cx); }
If polling the future returns Poll::Ready, we need to do some housekeeping:
- since we never need to poll the future again, we can drop it
- We update the state to not be
(state & !RUNNING & !SCHEDULED) | COMPLETED. If theHANDLEis dropped, then we also need to mark it asCLOSED. This is because the definition ofCLOSEDis when the output of theJoinHandlehas been consumed. If theJoinHandleis dropped, the output of theTaskis not needed so it’s technically “consumed”. - In the case that the output is not needed, which is when the
HANDLEis dropped or if the task was closed while running, we can drop theoutputearly since no one will consume it.
#![allow(unused)] fn main() { match poll { Poll::Ready(out) => { Self::drop_future(ptr); raw.output.write(out); // A place where the output will be stored in case it needs to be dropped. let mut output = None; // The task is now completed. // If the handle is dropped, we'll need to close it and drop the output. // We can drop the output if there is no handle since the handle is the // only thing that can retrieve the output from the raw task. let new = if state & HANDLE == 0 { (state & !RUNNING & !SCHEDULED) | COMPLETED | CLOSED } else { (state & !RUNNING & !SCHEDULED) | COMPLETED }; (*(raw.header as *mut Header)).state = new; // If the handle is dropped or if the task was closed while running, // now it's time to drop the output. if state & HANDLE == 0 || state & CLOSED != 0 { // Read the output. output = Some(raw.output.read()); } // Notify the awaiter that the task has been completed. (*(raw.header as *mut Header)).notify(None); drop(output); } Poll::Pending => { ... } } }
Let’s look at what happens if the future returns Poll::Pending. In most cases, all we need to do here is to unset the RUNNING bit of the task. However, in the case that the task was closed while running, we need to invoke drop_future to deallocate the future. We would also want to notify the awaiter if the Task is closed while running.
Note that the task can be closed while running in a few scenarios:
- the JoinHandle is dropped
- JoinHandle::cancel is called
- the task panics while running, which will automatically close the task.
Here is the code when the future returns Poll::Pending:
#![allow(unused)] fn main() { Poll::Pending => { // The task is still not completed. // If the task was closed while running, we'll need to unschedule in case it // was woken up and then destroy it. let new = if state & CLOSED != 0 { state & !RUNNING & !SCHEDULED } else { state & !RUNNING }; if state & CLOSED != 0 { Self::drop_future(ptr); } (*(raw.header as *mut Header)).state = new; // If the task was closed while running, we need to notify the awaiter. // If the task was woken up while running, we need to schedule it. // Otherwise, we just drop the task reference. if state & CLOSED != 0 { // Notify the awaiter that the future has been dropped. (*(raw.header as *mut Header)).notify(None); } else if state & SCHEDULED != 0 { // The thread that woke the task up didn't reschedule it because // it was running so now it's our responsibility to do so. Self::schedule(ptr); ret = true; } } }
Finally, drop_task is called to potentially deallocate the task:
#![allow(unused)] fn main() { Self::drop_task(ptr); }
Here is the implementation for drop_task:
#![allow(unused)] fn main() { unsafe fn drop_task(ptr: *const ()) { let raw = Self::from_ptr(ptr); // Decrement the reference count. let refs = Self::decrement_references(&mut *(raw.header as *mut Header)); let state = (*raw.header).state; // If this was the last reference to the task and the `JoinHandle` has been // dropped too, then destroy the task. if refs == 0 && state & HANDLE == 0 { Self::destroy(ptr); } } }
Note that drop_task only deallocates the task if the reference count is 0 and the HANDLE is dropped. The HANDLE is not part of the reference count.
The goal of this section is to showcase the type of challenges that one can expect when building an asynchronous runtime. One needs to pay particular attention to deallocating memory as early as possible and be careful about updating the state of the Task in different scenarios.
Code References
To check out my toy implementation or Glommio’s implementation, check out:
My Toy Implementation
Glommio
TaskQueue
An executor needs to store a list of scheduled Tasks. This is what the TaskQueue is for, it holds a collection of managed tasks.
Here is the implemnetation for the TaskQueue:
#![allow(unused)] fn main() { pub(crate) struct TaskQueue { // contains the actual queue of Tasks pub(crate) ex: Rc<TaskQueueExecutor>, // The invariant around active is that when it's true, // it needs to be inside the active_executors pub(crate) active: bool, } pub(crate) struct TaskQueueExecutor { local_queue: LocalQueue, name: String, } struct LocalQueue { queue: RefCell<VecDeque<Task>>, } }
The TaskQueue contains a TaskQueueExecutor which contains the actual LocalQueue which holds a VecDeque of Tasks.
The two most important methods on a TaskQueueExecutor are:
- create_task
- spawn_and_schedule
create_task
Create task allocates the Task and creates the corresponding JoinHandle. Note that creating a Task requires providing a schedule method. The provided schedule method is a closure that simply pushes the task onto the local_queue.
#![allow(unused)] fn main() { // Creates a Task with the Future and push it onto the queue by scheduling fn create_task<T>( &self, executor_id: usize, tq: Rc<RefCell<TaskQueue>>, future: impl Future<Output = T>, ) -> (Task, JoinHandle<T>) { let tq = Rc::downgrade(&tq); let schedule = move |task| { let tq = tq.upgrade(); if let Some(tq) = tq { { tq.borrow().ex.as_ref().local_queue.push(task); } { LOCAL_EX.with(|local_ex| { let mut queues = local_ex.queues.as_ref().borrow_mut(); queues.maybe_activate_queue(tq); }); } } }; create_task(executor_id, future, schedule) } }
spawn_and_schedule
#![allow(unused)] fn main() { pub(crate) fn spawn_and_schedule<T>( &self, executor_id: usize, tq: Rc<RefCell<TaskQueue>>, future: impl Future<Output = T>, ) -> JoinHandle<T> { let (task, handle) = self.create_task(executor_id, tq, future); task.schedule(); handle } }
spawn_and_schedule simply creates the task and invokes the schedule method which pushes the task onto the LocalQueue of the TaskQueueExecutor.
Code References
To check out my toy implementation or Glommio’s implementation, check out:
My Toy Implementation
Glommio
- TaskQueue
- LocalExecutor - My toy implementation calls the
LocalExecutortheTaskQueueExecutor
Waker
Earlier, we saw that when RawTask::run is called, run creates a waker which is used to poll the user-provided Future. In this section, we look at how the Waker instance is created.
To create a waker in Rust, we need to pass a RawWakerVTable to the Waker constructor.
Here is the vtable for the task:
impl<F, R, S> RawTask<F, R, S>
where
F: Future<Output = R>,
S: Fn(Task),
{
const RAW_WAKER_VTABLE: RawWakerVTable = RawWakerVTable::new(
Self::clone_waker,
Self::wake,
Self::wake_by_ref,
Self::drop_waker,
);
The most important method here is the wake method, which is invoked when Waker::wake is called.
The Waker::wake() simply reschedules the task by pushing it onto the TaskQueue. Here is the implementation of wake and wake_by_ref:
#![allow(unused)] fn main() { unsafe fn wake(ptr: *const ()) { Self::wake_by_ref(ptr); Self::drop_waker(ptr); } /// Wakes a waker. Ptr is the raw task. unsafe fn wake_by_ref(ptr: *const ()) { let raw = Self::from_ptr(ptr); let state = (*raw.header).state; // If the task is completed or closed, it can't be woken up. if state & (COMPLETED | CLOSED) == 0 { // If the task is already scheduled do nothing. if state & SCHEDULED == 0 { // Mark the task as scheduled. (*(raw.header as *mut Header)).state = state | SCHEDULED; if state & RUNNING == 0 { // Schedule the task. Self::schedule(ptr); } } } } }
The schedule method is passed to the task when the task is created and it looks something like:
let schedule = move |task| {
let task_queue = tq.upgrade();
task_queue.local_queue.push(task);
};
create_task(executor_id, future, schedule)
Finally, here is the code that actually creates the waker which is used to poll the user-defined future.
#![allow(unused)] fn main() { let waker = ManuallyDrop::new(Waker::from_raw(RawWaker::new(ptr, &Self::RAW_WAKER_VTABLE))); let cx = &mut Context::from_waker(&waker); let poll = <F as Future>::poll(Pin::new_unchecked(&mut *raw.future), cx); }
Code References
To check out my toy implementation or Glommio’s implementation, check out:
My Toy Implementation
Glommio
LocalExecutor
Now that we know how the task and task queue is implemented, we can perform a deep dive
into how the Executor::Run and Executor::spawn methods are implemented.
As a refresher, here’s an example of an executor running a task and spawning a task onto the executor.
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); let res = local_ex.run(async { let handle = local_ex.spawn(async_write_file()); handle.await; }); }
Single Threaded
It’s important to understand that the LocalExecutor is single-threaded. This means that the executor can only be run on the thread that created it. LocalExecutor doesn’t implement the Send or Sync trait, so you cannot move a LocalExecutor across threads. This makes it easier to reason about the methods on LocalExecutor since it’s safe to assume that only one function invocation can be executing at any time. In other words, there won’t be two invocations of run on the same executor at once.
Internals
Let’s look at the internals of an Executor:
#![allow(unused)] fn main() { pub(crate) struct LocalExecutor { pub(crate) id: usize, pub(crate) queues: Rc<RefCell<QueueManager>>, } }
A LocalExecutor contains a QueueManager. As explained earlier, a QueueManager contains all the Task Queues.
#![allow(unused)] fn main() { pub(crate) struct QueueManager { pub active_queues: BinaryHeap<Rc<RefCell<TaskQueue>>>, pub active_executing: Option<Rc<RefCell<TaskQueue>>>, pub available_queues: AHashMap<usize, Rc<RefCell<TaskQueue>>>, } }
At any time, a QueueManager is actively working on at most one TaskQueue. The active_queues property stores the TaskQueues that are not empty. Any TaskQueue inside active_queues is also inside available_queues. A TaskQueue is removed from active_queues whenever it’s empty.
Now, we can finally look at run, the core method of a LocalExecutor.
Deep Dive into Run
The run method runs the executor until the provided future completes. Here is its implementation:
#![allow(unused)] fn main() { pub fn run<T>(&self, future: impl Future<Output = T>) -> T { assert!( !LOCAL_EX.is_set(), "There is already an LocalExecutor running on this thread" ); LOCAL_EX.set(self, || { let join_handle = self.spawn(async move { future.await }); let waker = dummy_waker(); let cx = &mut Context::from_waker(&waker); pin!(join_handle); loop { if let Poll::Ready(t) = join_handle.as_mut().poll(cx) { // can't be canceled, and join handle is None only upon // cancellation or panic. So in case of panic this just propagates return t.unwrap(); } // TODO: I/O work self.run_task_queues(); } }) } }
Let’s break down run line by line. First, run makes sure that no other executors are running on the same thread. LOCAL_EX is a thread local storage key defined as:
#![allow(unused)] fn main() { scoped_tls::scoped_thread_local!(static LOCAL_EX: LocalExecutor); }
Next, it calls spawn to create and schedule the task onto the TaskQueue.
It then loops until the future is completed. It’s super important to understand that the poll method here doesn’t actually poll the user-provided future. It simply polls the JoinHandle, which checks if the COMPLETED flag on the task’s state is set.
Since the executor is single-threaded, looping alone won’t actually progress the underlying future. Therefore, in each loop, the executor calls the run_task_queues method.
run_task_queues simply loops and calls run_one_task_queue until there are no more tasks left in the TaskQueue.
#![allow(unused)] fn main() { fn run_task_queues(&self) -> bool { let mut ran = false; loop { // TODO: Check if prempt if !self.run_one_task_queue() { return false; } else { ran = true; } } ran } }
run_one_task_queue sets the active_executing queue to one of the active_queues. It then loops until until there are no more tasks in that TaskQueue.
In each loop, it calls get_task which pops a task from the TaskQueue.
#![allow(unused)] fn main() { fn run_one_task_queue(&self) -> bool { let mut q_manager = self.queues.borrow_mut(); let size = q_manager.active_queues.len(); let tq = q_manager.active_queues.pop(); match tq { Some(tq) => { q_manager.active_executing = Some(tq.clone()); drop(q_manager); loop { // TODO: Break if pre-empted or yielded let tq = tq.borrow_mut(); if let Some(task) = tq.get_task() { drop(tq); task.run(); } else { break; } } true } None => { false } } } }
To summarize, run spawns a task onto one of the task queues. The executor then runs one task_queue at a time to completion until the spawned task is COMPLETED. The most important concept to remember here is that none of the task is blocking. Whenever one of the task is about to be run, it is popped from the TaskQueue. It won’t be scheduled back onto the TaskQueue until its waker is invoked, which is when the thing blocking it is no longer blocking. In other words, the executor will move from one task to another without waiting on any blocking code.
spawn
The spawn method is how a user can spawn a task onto the executor.
spawn allows the developer to create two tasks that run concurrently instead of sequentially:
#![allow(unused)] fn main() { let res = local_ex.run(async { let handle1 = local_ex.spawn(async_write_file()); let handle2 = local_ex.spawn(async_write_file()); handle1.await; handle2.await; }); }
This is the implementation of spawn:
Spawn_local simply finds the LocalExecutor on the current thread and calls LocalExecutor::spawn. Here is the implementation of spawn:
#![allow(unused)] fn main() { pub(crate) fn spawn<T>(&self, future: impl Future<Output = T>) -> JoinHandle<T> { let active_executing = self.queues.borrow().active_executing.clone(); let tq = active_executing .clone() // this clone is cheap because we clone an `Option<Rc<_>>` .or_else(|| self.get_default_queue()) .unwrap(); let tq_executor = tq.borrow().ex.clone(); tq_executor.spawn_and_schedule(self.id, tq, future) } pub(crate) fn spawn_and_schedule<T>( &self, executor_id: usize, tq: Rc<RefCell<TaskQueue>>, future: impl Future<Output = T>, ) -> JoinHandle<T> { let (task, handle) = self.create_task(executor_id, tq, future); task.schedule(); handle } }
Spawn gets the active executing TaskQueue, creates a task and schedules the Task onto the TaskQueue.
To summarize, spawn_local simply schedules a Task onto the LocalExecutor's actively executing TaskQueue.
Code References
To check out my toy implementation or Glommio’s implementation, check out:
My Toy Implementation
Glommio
Join Handle
When a task is spawned, the user needs a way to consume the output or cancel the task. This is what the JoinHandle does - it allows the user to consume the output of the task or cancel the task.
After a task is spawned, the way to consume the output is to await the handle. For example:
#![allow(unused)] fn main() { let handle = spawn_local(async { 1 + 3 }); let res: i32 = handle.await; }
Awaiting is also a control flow mechanism that allows the user to control the execution order of two tasks. For example, in the following method, the second task won’t be spawned until the first task is completed.
#![allow(unused)] fn main() { let handle = spawn_local(...); handle.await; spawn_local(...); }
Since the JoinHandle can be awaited, it must implement the Future trait. So what does the poll method of the JoinHandle do?
Poll
Polling a JoinHandle doesn’t actually poll the user-provided future to progress it. The only way for the user-provided future to be polled is with the RawTask::run method which is invoked by the LocalExecutor’s run method.
Before we look into what poll does, let’s first look at the different ways a JoinHandle is used.
There are two different ways a JoinHandle gets created:
LocalExecutor::runspawn_local/spawn_local_into
LocalExecutor::run
Here is a code snippet for the run method:
#![allow(unused)] fn main() { LOCAL_EX.set(self, || { let waker = dummy_waker(); let cx = &mut Context::from_waker(&waker); let join_handle = self.spawn(async move { future.await }); pin!(join_handle); loop { if let Poll::Ready(t) = join_handle.as_mut().poll(cx) { return t.unwrap(); } self.run_task_queues(); } }) }
We can see that join_handle is only used as a way to inspect whether the user-provided future is completed or not. Therefore, a dummy_waker is used. A dummy_waker is a Waker that doesn’t do anything when wake() is invoked.
spawn_local / spawn_local_into
Earlier, we talked about how the compiler converts the body of an async function into a state machine, where each .await call represents a new state. We also learned that when the state machine is polled and it returns Poll::Pending, then the executor wouldn’t want to poll the state machine again until the blocking task is completed. Therefore, the blocking task needs to store the waker of the parent task and notify it when the parent task can be polled again.
This is what the JoinHandle created from spawn_local and spawn_local_into needs to do. It stores the waker from the poll method and notifies the executor that the parent task can be polled again.
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); local_ex.run(async { let join_handle = spawn_local(async_write_file()); join_handle.await; }); }
In the example above, the run method would spawn the Future created from the async block as follows:
#![allow(unused)] fn main() { let join_handle = self.spawn(async move { future.await }); }
Let’s call this Task A. When Task A gets polled, it executes the following two lines of code:
#![allow(unused)] fn main() { let join_handle = spawn_local(async_write_file()); join_handle.await; }
Let’s call the task associated with async_write_file as Task B. When the join handle for Task B is polled, Task B is most likely not complete yet. Therefore, Task B needs to store the Waker from the poll method. The Waker would schedule Task A back onto the executor when .wake() is invoked.
Deep Dive into Poll
Here is the rough structure of the JoinHandle's poll method. Notice that the Output type is Option<R> instead of R. The poll method returns Poll::Ready(None) if the task is CLOSED. In general, there are three scenarios to cover:
- if the task is
CLOSED - if the task is not
COMPLETED - if the task is neither
CLOSEDnor notCOMPLETED
#![allow(unused)] fn main() { impl<R> Future for JoinHandle<R> { type Output = Option<R>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let ptr = self.raw_task.as_ptr(); let header = ptr as *mut Header; unsafe { let state = (*header).state; if state & CLOSED != 0 { ... } if state & COMPLETED == 0 { ... } ... } } } }
Let’s first look at what happens if the task is CLOSED.
#![allow(unused)] fn main() { if state & CLOSED != 0 { // If the task is scheduled or running, we need to wait until its future is // dropped. if state & (SCHEDULED | RUNNING) != 0 { // Replace the waker with one associated with the current task. (*header).register(cx.waker()); return Poll::Pending; } // Even though the awaiter is most likely the current task, it could also be // another task. (*header).notify(Some(cx.waker())); return Poll::Ready(None); } }
If the task is closed, we notify the awaiter and return None. However, in the case that it’s CLOSED but still SCHEDULED | RUNNING, that means the future hasn’t dropped yet. My understanding of this is that we are playing safe here, but let me know if there’s another reason why we need to return Poll::Pending when the future hasn’t dropped yet.
Next, if the state is not COMPLETED, then we simply register the waker as the awaiter and return Poll::Pending.
#![allow(unused)] fn main() { if state & COMPLETED == 0 { // Replace the waker with one associated with the current task. (*header).register(cx.waker()); return Poll::Pending; } }
Finally, in the case that the task’s state is not CLOSED and COMPLETED, then we mark the task as CLOSED since the output has been consumed. We notify the awaiter. And we return Poll::Ready(Some(output).
#![allow(unused)] fn main() { (*header).state |= CLOSED; // Notify the awaiter. Even though the awaiter is most likely the current // task, it could also be another task. (*header).notify(Some(cx.waker())); // Take the output from the task. let output = ((*header).vtable.get_output)(ptr) as *mut R; Poll::Ready(Some(output.read())) }
Cancel
Another responsibility of JoinHandle is that it’s a handle for the user to cancel a task. I won’t go into too much detail about how cancel works. But the general idea is that canceling a task means that the future will not be polled again. However, if the task is already COMPLETED, canceling a JoinHandle does nothing.
Code References
To check out my toy implementation or Glommio’s implementation, check out:
Mini Async Runtime
Glommio
Life of a Task
This page illustrates the lifecycle of a task and how it interacts with the various parts of the executor.
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); let task1_result = local_ex.run(async { let task2_handle = spawn_local({ async_read_file(...).await }); task2_handle.await }); }
Spawning the Task
When the LocalExecutor is created, a default TaskQueue is created. When local_ex.run(...) is called, the executor spawns a task with the Future created from the async block. It creates a task and schedules the task onto the default TaskQueue. Let’s name this task as Task1.
Running Task1
Spawning the task would create a JoinHandle for Task1. The LocalExecutor creates a loop that will only exit when Task1 is completed. The executor verifies when the task is completed by polling the JoinHandle. If it’s completed, the loop exits, and the output of the task is returned. Otherwise, the executor begins running tasks from active task queues.
To run the task, the executor would go through all the TaskQueues and execute all the tasks in them. It does so by creating an outer loop that loops through theTaskQueues and creating an inner loop that runs all the tasks in each TaskQueue.
To run a task, the executor pops the task from the task queue and runs it. When the task is run, it creates a Waker with the RAW_WAKER_VTABLE. Let’s call the created Waker Waker1. Waker1's responsibility is to reschedule Task1 onto the TaskQueue when wake() is called.
Next, the executor polls the user-provided Future with Waker1. As a reminder, the user-provided Future is the Future created from the following async block:
#![allow(unused)] fn main() { async { let task2_handle = spawn_local(async { async_read_file(...).await }); task2_handle.await } }
When the Future is polled, it would first spawn a task with the Future created from async { async_read_file(...).await }. Let’s call the spawned task Task2. Spawning Task2 would also create a JoinHandle for it.
Next, handle.await is called, which would poll the JoinHandle. Since Task2 is not complete, the waker is registered as Task2’s awaiter. This waker corresponds to Waker1. The idea is that Task2 is blocking Task1. So when Task2 completes, Waker1::wake() would be invoked. This would notify the executor that Task1 is ready to progress again by scheduling Task1 onto the TaskQueue.
Running Task2
After Task1::run() completes, we are back to the inner loop that runs all the tasks from the active TaskQueue. Since Task2 is now in the TaskQueue, the executor would pop it off from the TaskQueue to execute it.
When Task2 is run, a Waker for Task2 is created. Let’s call it Waker2. Next, the Future created from async { async_read_file(...).await } would be polled with Waker2. Since we haven’t covered how I/O works, let’s treat async_read_file as a black box. All we need to know is that when the operation is completed, Waker2::wake() will be invoked which will reschedule Task2.
After async_read_file is completed, Task2 is rescheduled back on the TaskQueue. We are back on the inner loop that runs the default TaskQueue. It would pop Task2 off the TaskQueue and poll it. This time, the Future is completed. This would notify Task1 that Task2 has been completed by waking up Waker1. This would reschedule Task1 and push it back onto the TaskQueue.
Completing Task1
We are back to the loop that runs the default TaskQueue. It would pop Task1 from the TaskQueue and run it. It would poll the Future which would return Poll::Ready. Finally, we can exit both the inner loop and the outer loop since there are no more tasks in any of the TaskQueues to run.
After run_task_queues finishes executing, the executor would [poll Task1's JoinHandle again](https://github.com/brianshih1/mini-glommio/blob/7025a02d91f19e258d69e966f8dfc98eeeed4ecc/src/executor/local_executor.rs#L77), which would return Poll::Pending. Then the executor can finally return the output result.
Thread Pinning
Thread-per-core is a programming paradigm in which developers are not allowed to spawn new threads to run tasks. Instead, each core only runs a single thread. This is to avoid expensive context switches and avoid using synchronization primitives such as locks. Check out this excellent blog by Glommio to explain the benefits of the thread-per-core archicture.
API
In this section, we will enable the developer to create a LocalExecutor that only runs on a particular CPU. In this code snippet below, we create an executor that only runs on Cpu 0 with the help of the LocalExecutorBuilder.
#![allow(unused)] fn main() { // The LocalExecutor will now only run on Cpu 0 let builder = LocalExecutorBuilder::new(Placement::Fixed(0)); let local_ex = builder.build(); let res = local_ex.run(async { ... }); }
By creating N executors and binding each executor to a specific CPU, the developer can implement a thread-per-core system.
Implementation
sched_setaffinity
To force a thread to run on a particular CPU, we will be modifying the thread's CPU affinity mask by using Linux's sched_affinity command. As specified in Linux’s manual page, After a call to **sched_setaffinity**(), the set of CPUs on which the thread will actually run is the intersection of the set specified in the *mask* argument and the set of CPUs actually present on the system..
LocalExecutor
We modify LocalExecutor's constructor to take a list of CPUs as its parameter. It then calls bind_to_cpu_set
#![allow(unused)] fn main() { impl LocalExecutor { pub fn new(cpu_binding: Option<impl IntoIterator<Item = usize>>) -> Self { match cpu_binding { Some(cpu_set) => bind_to_cpu_set(cpu_set), None => {} } LocalExecutor { ... } } pub(crate) fn bind_to_cpu_set(cpus: impl IntoIterator<Item = usize>) { let mut cpuset = nix::sched::CpuSet::new(); for cpu in cpus { cpuset.set(cpu).unwrap(); } let pid = nix::unistd::Pid::from_raw(0); nix::sched::sched_setaffinity(pid, &cpuset).unwrap(); } ... } }
In bind_to_cpu_set, the pid is set to 0 because the manual page says that If *pid* is zero, then the calling thread is used.
Placement
Next, we introduce Placements. A Placement is a policy that determines what CPUs the LocalExecutor will run on. Currently, there are two Placements. We may add more in Phase 4.
#![allow(unused)] fn main() { pub enum Placement { /// The `Unbound` variant creates a [`LocalExecutor`]s that are not bound to /// any CPU. Unbound, /// The [`LocalExecutor`] is bound to the CPU specified by /// `Fixed`. Fixed(usize), } }
Placement::Unbound means that the LocalExecutor is not bound to any CPU. Placement::Fixed(cpu_id) means that the LoccalExecutor is bound to the specified CPU.
LocalExecutorBuilder
Finally, all the LocalExecutorBuilder does is that it transforms a Placement into a list of CPUs that will be passed into LocalExecutor's constructor.
#![allow(unused)] fn main() { pub(crate) struct LocalExecutorBuilder { placement: Placement, } impl LocalExecutorBuilder { pub fn new(placement: Placement) -> LocalExecutorBuilder { LocalExecutorBuilder { placement } } pub fn build(self) -> LocalExecutor { let cpu_binding = match self.placement { Placement::Unbound => None::<Vec<usize>>, Placement::Fixed(cpu) => Some(vec![cpu]), }; let mut ex = LocalExecutor::new(cpu_binding); ex.init(); ex } } }
When Placement::Fixed(cpu) is provided, the LocalExecutorBuilder simply creates the LocalExecutor with vec![cpu] as the specified CPU.
What is Asynchronous I/O?
So far, we have built an executor that can spawn and run tasks. However, we haven't talked about how it can perform I/O, such as making a network call or reading from disk.
A simple approach to I/O would be to just wait for the I/O operation to complete. But such an approach, called synchronous I/O or blocking I/O would block the single-threaded executor from performing any other tasks concurrently.
What we want instead is asynchronous I/O. In this approach, performing I/O won’t block the calling thread. Instead, the executor switches to other tasks after making nonblocking I/O call and only resume the task when the kernel notifies the executor that the I/O operation is complete.
In this section, we discuss how our executor can perform asynchronous I/O. First, let's look at the primitives that enable to do that.
Prerequisites - Building Blocks
Nonblocking Mode
In most programming languages, I/O operations are blocking by default. For example, in the following example the TcpListener::accept call will block the thread until a new TCP connection is established.
#![allow(unused)] fn main() { let listener = TcpListener::bind("127.0.0.1:8080").unwrap(); listener.accept(); }
Nonblocking I/O
The first step towards asynchronous I/O is turning a blocking I/O operation into a non-blocking one.
In Linux, it is possible to do nonblocking I/O on sockets and files by setting the O_NONBLOCK flag on the file descriptors.
Here’s how you can set the file descriptor for a socket to be non-blocking:
#![allow(unused)] fn main() { let listener = std::net::TcpListener::bind("127.0.0.1:8080").unwrap(); let raw_fd = listener.as_raw_fd(); fcntl(raw_fd, FcntlArg::F_SETFL(OFlag::O_NONBLOCK)) }
Setting the file descriptor for the TcpListener to nonblocking means that the next I/O operation would immediately return. To check if the operation is complete, you have to manually poll the file descriptor.
Rust’s std library has helper methods such as Socket::set_blocking to set a file descriptor to be nonblocking:
#![allow(unused)] fn main() { let l = std::net::TcpListener::bind("127.0.0.1:8080").unwrap(); l.set_nonblocking(true).unwrap(); }
Polling
As mentioned above, after setting a socket’s file descriptor to be non-blocking, you have to manually poll the file descriptor to check if the I/O operation is completed. Under non-blocking mode, the TcpListener::Accept method returns Ok if the I/O operation is successful or an error with kind io::ErrorKind::WouldBlock is returned.
In the following example, we loop until the I/O operation is ready by repeatedly calling accept:
#![allow(unused)] fn main() { let l = std::net::TcpListener::bind("127.0.0.1:8080").unwrap(); l.set_nonblocking(true).unwrap(); loop { // the accept call let res = l.accept(); match res { Ok((stream, _)) => { handle_connection(stream); break; } Err(err) => if err.kind() == io::ErrorKind::WouldBlock {}, } } }
While this works, repeatedly calling accept in a loop is not ideal. Each call to TcpListener::accept is an expensive call to the kernel.
This is where system calls like select, poll, epoll, aio, io_uring come in. These calls allow you to monitor a bunch of file descriptors and notify you when one or more of them are ready. This reduces the need for constant polling and makes better use of system resources.
Glommio uses io_uring. One of the things that make io_uring stand out compared to other system calls is that it presents a uniform interface for both sockets and files. This is a huge improvement from system calls like epoll that doesn’t support files while aio only works with a subset of files (linus-aio only supports O_DIRECT files). In the next page, we take a quick glance at how io_uring works.
Io_uring
In this page, I’ll provide a surface-level explanation of how io_uring works. If you want a more in-depth explanation, check out this tutorial or this redhat article.
As mentioned, io_uring manages file descriptors for the users and lets them know when one or more of them are ready.
Each io_uring instance is composed of two ring buffers - the submission queue and the completion queue.
To register interest in a file descriptor, you add an SQE to the tail of the submission queue. Adding to the submission queue doesn’t automatically send the requests to the kernel, you need to submit it via the io_uring_enter system call. Io_uring supports batching by allowing you to add multiple SQEs to the ring before submitting.
The kernel processes the submitted entries and adds completion queue events (CQEs) to the completion queue when it is ready. While the order of the CQEs might not match the order of the SQEs, there will be one CQE for each SQE, which you can identify by providing user data.
The user can then check the CQE to see if there are any completed I/O operations.
Using io_uring for TcpListener
Let’s look at how we can use IoUring to manage the accept operation for a TcpListener. We will be using the iou crate, a library built on top of liburing, to create and interact with io_uring instances.
#![allow(unused)] fn main() { let l = std::net::TcpListener::bind("127.0.0.1:8080").unwrap(); l.set_nonblocking(true).unwrap(); let mut ring = iou::IoUring::new(2).unwrap(); unsafe { let mut sqe = ring.prepare_sqe().expect("failed to get sqe"); sqe.prep_poll_add(l.as_raw_fd(), iou::sqe::PollFlags::POLLIN); sqe.set_user_data(0xDEADBEEF); ring.submit_sqes().unwrap(); } l.accept(); let cqe = ring.wait_for_cqe().unwrap(); assert_eq!(cqe.user_data(), 0xDEADBEEF); }
In this example, we first create a [TcpListener](<https://doc.rust-lang.org/stable/std/net/struct.TcpListener.html>) and set it to non-blocking. Next, we create an io_uring instance. We then register interest in the socket’s file descriptor by making a call to prep_poll_add (a wrapper around Linux’s io_uring_prep_poll_add call). This adds a SQE entry to the submission queue which will trigger a CQE to be posted when there is data to be read.
We then call accept to accept any incoming TCP connections. Finally, we call wait_for_cqe, which returns the next CQE, blocking the thread until one is ready if necessary. If we wanted to avoid blocking the thread in this example, we could’ve called peek_for_cqe which peeks for any completed CQE without blocking.
Efficiently Checking the CQE
You might be wondering - if we potentially need to call peek_for_cqe() repeatedly until it is ready, how is this different from calling listener.accept() repeatedly?
The difference is that accept is a system call while peek_for_cqe, which calls io_uring_peek_batch_cqe under the hood, is not a system call. This is due to the unique property of io_uring such that the completion ring buffer is shared between the kernel and the user space. This allows you to efficiently check the status of completed I/O operations.
API
Our goal here is to implement a set of internal APIs to make it easy to convert synchronous I/O operations into asynchronous ones.
Here are the rough steps to convert a blocking I/O operation into an asynchronous one:
- we set the file descriptor to non-blocking
- we perform the non-blocking operation
- we tell
io_uringto monitor the file descriptor by submitting anSQE - we store the poller’s
wakerand invokewake()when the I/O operation is complete. We detect when an I/O operation is complete when the correspondingCQEis posted to theio_uring's completion queue.
To make it easier to implement new asynchronous operations, we introduce Async, an adapter for I/O types inspired by the async_io crate. Async abstracts away the steps listed above so that developers who build on top of Async don’t have to worry about things like io_uring, Waker, O_NONBLOCK, etc.
Here is how you use the Async adapter to implement an asynchronous TcpListener with an asynchronous accept method:
#![allow(unused)] fn main() { impl Async<TcpListener> { pub fn bind<A: Into<SocketAddr>>(addr: A) -> io::Result<Async<TcpListener>> { let addr = addr.into(); let listener = TcpListener::bind(addr)?; Ok(Async::new(listener)?) } pub async fn accept(&self) -> io::Result<(Async<TcpStream>, SocketAddr)> { let (stream, addr) = self.read_with(|io| io.accept()).await?; Ok((Async::new(stream)?, addr)) } } }
Here is how you can use the Async<TcpListener> inside an executor to perform asynchronous I/O:
#![allow(unused)] fn main() { let local_ex = LocalExecutor::default(); let res = local_ex.run(async { let listener = Async::<TcpListener>::bind(([127, 0, 0, 1], 8080)).unwrap(); let (stream, _) = listener.accept().await.unwrap(); handle_connection(stream); }); }
Next, let's look at what the Async adapter actually does.
Implementation Details
Core abstractions
We can break down how the executor performs asynchronous I/O into 3 steps:
- setting the I/O handle to be non-blocking by setting the
O_NONBLOCKflag on the file descriptor - performing the non-blocking operation and registering interest in
io_uringby submitting aSQEto theio_uringinstance'ssubmission_queue - polling the
io_uring's completion queue to check if there is a correspondingCQE, which indicates that the I/O operation has been completed. If it's completed, process it by resuming the blocked task.
To accomplish these, we will introduce a few new abstractions: Async, Source, and the Reactor.
Async
Async is a wrapper around the I/O handle (e.g. TcpListener). It contains helper methods to make converting blocking operations into asynchronous operations easier.
Here is the Async struct:
#![allow(unused)] fn main() { pub struct Async<T> { /// A source registered in the reactor. source: Source, /// The inner I/O handle. io: Option<Box<T>>, } }
Source
The Source is a bridge between the executor and the I/O handle. It contains the rwa file descriptor for the I/O event as well as properties that are relevant to the executor. For example, it contains wakers for blocked tasks waiting for the I/O operation to complete.
#![allow(unused)] fn main() { pub struct Source { pub(crate) inner: Pin<Rc<RefCell<InnerSource>>>, } /// A registered source of I/O events. pub(crate) struct InnerSource { /// Raw file descriptor on Unix platforms. pub(crate) raw: RawFd, /// Tasks interested in events on this source. pub(crate) wakers: Wakers, pub(crate) source_type: SourceType, ... } }
Reactor
Each executor has a Reactor. The Reactor is an abstraction around the io_uring instance. It provides simple APIs to interact with the io_uring instance.
#![allow(unused)] fn main() { pub(crate) struct Reactor { // the main_ring contains an io_uring instance main_ring: RefCell<SleepableRing>, source_map: Rc<RefCell<SourceMap>>, } struct SleepableRing { ring: iou::IoUring, in_kernel: usize, submission_queue: ReactorQueue, name: &'static str, source_map: Rc<RefCell<SourceMap>>, } struct SourceMap { id: u64, map: HashMap<u64, Pin<Rc<RefCell<InnerSource>>>>, } }
As we can see, the Reactor holds a SleepableRing, which is just a wrapper around an iou::IoUring instance. Glommio uses the iou crate to interact with Linux kernel’s io_uring interface.
The Reactor also contains a SourceMap, which contains a HashMap that maps a unique ID to a Source. The unique ID is the same ID used as the SQE's user_data. This way, when a CQE is posted to the io_uring's completion queue, we can tie it back to the corresponding Source.
Step 1 - Setting the O_NONBLOCK Flag
The first step to asynchronous I/O is to change the I/O handle to be nonblocking by setting the O_NONBLOCK flag.
API
Async::new(handle) is responsible for setting the I/O handle to be nonblocking.
Implementation
Async::new(handle) is the constructor of the Async struct. For example, here is how you create an instance of Async<TcpListener>:
#![allow(unused)] fn main() { let listener = TcpListener::bind(addr)?; Async::new(listener); }
Here is the implementation of Async::new:
#![allow(unused)] fn main() { impl<T: AsRawFd> Async<T> { pub fn new(io: T) -> io::Result<Async<T>> { Ok(Async { source: get_reactor().create_source(io.as_raw_fd()), io: Some(Box::new(io)), }) } } }
The get_reactor() method retrieves the Reactor for the executor running on the current thread. The create_source method, as shown below, sets the O_NONBLOCK flag for the handle with fcntl.
#![allow(unused)] fn main() { impl Reactor { ... pub fn create_source(&self, raw: RawFd) -> Source { fcntl(raw, FcntlArg::F_SETFL(OFlag::O_NONBLOCK)).unwrap(); self.new_source(raw, SourceType::PollableFd) } fn new_source(&self, raw: RawFd, stype: SourceType) -> Source { Source::new(raw, stype, None) } } }
Step 2 - Submitting a SQE
The second step to asynchronous I/O is to ask io_uring to monitor a file descriptor on when it’s ready to perform I/O by submitting a SQE entry.
API
Async has two methods which will perform an I/O operation and wait until it is completed:
#![allow(unused)] fn main() { // Performs a read I/O operation and wait until it is readable pub async fn read_with<R>(&self, op: impl FnMut(&T) -> io::Result<R>) -> io::Result<R> // Performs a write I/O operation and wait until it is writable pub async fn write_with<R>(&self, op: impl FnMut(&T) -> io::Result<R>) -> io::Result<R> }
For example, here is how you can use the read_with method to implement Async<TcpListener>'s accept method:
#![allow(unused)] fn main() { impl Async<TcpListener> { ... pub async fn accept(&self) -> io::Result<(Async<TcpStream>, SocketAddr)> { let (stream, addr) = self.read_with(|io| io.accept()).await?; ... } } }
Implementation
Here is the implementation of read_with:
#![allow(unused)] fn main() { impl<T> Async<T> { ... pub async fn read_with<R>(&self, op: impl FnMut(&T) -> io::Result<R>) -> io::Result<R> { let mut op = op; loop { match op(self.get_ref()) { Err(err) if err.kind() == io::ErrorKind::WouldBlock => { } res => return res, } // this waits until the I/O operation is readable (completed) self.source.readable().await?; } } pub fn get_ref(&self) -> &T { self.io.as_ref().unwrap() } } }
It first performs the I/O operation via the call to op(self.get_ref()). It then waits for the I/O operation is completed with self.source.readable().await.
Source::readable is an async method that does a few things:
- It stores the
wakerof thePollerby invokingself.add_waiter(cx.waker().clone()). This way, when the executor detects that the I/O operation is completed, it can invokewake()on the stored waker. The mechanism for waking up the unblocked task is explained in the next page. - It adds a
SQEto theio_uringinstance in the Reactor by callingget_reactor().sys.interest(self, true, false).
Here is the implementation of Source::readable:
#![allow(unused)] fn main() { impl Source { ... /// Waits until the I/O source is readable. pub(crate) async fn readable(&self) -> io::Result<()> { future::poll_fn(|cx| { if self.take_result().is_some() { return Poll::Ready(Ok(())); } self.add_waiter(cx.waker().clone()); get_reactor().sys.interest(self, true, false); Poll::Pending }) .await } pub(crate) fn take_result(&self) -> Option<io::Result<usize>> { self.inner.borrow_mut().wakers.result.take() } pub(crate) fn add_waiter(&self, waker: Waker) { self.inner.borrow_mut().wakers.waiters.push(waker); } } }
Here is the implementation of the Reactor::interest method invoked. It first computes the PollFlags that will be used to construct the SQE. It then calls queue_request_into_ring to add a SQE entry to the submission queue.
#![allow(unused)] fn main() { impl Reactor { ... pub(crate) fn interest(&self, source: &Source, read: bool, write: bool) { let mut flags = common_flags(); if read { flags |= read_flags(); } if write { flags |= write_flags(); } queue_request_into_ring( &mut *self.main_ring.borrow_mut(), source, UringOpDescriptor::PollAdd(flags), &mut self.source_map.clone(), ); } } /// Epoll flags for all possible readability events. fn read_flags() -> PollFlags { PollFlags::POLLIN | PollFlags::POLLPRI } /// Epoll flags for all possible writability events. fn write_flags() -> PollFlags { PollFlags::POLLOUT } }
queue_request_into_ring
This method simply adds a UringDescriptor onto the SleepableRing's queue. Note that queueing the request into ring doesn’t actually add a SQE to the io_uring's submission_queue. It just adds it to the submission_queue property on the SleepableRing.
#![allow(unused)] fn main() { fn queue_request_into_ring( ring: &mut (impl UringCommon + ?Sized), source: &Source, descriptor: UringOpDescriptor, source_map: &mut Rc<RefCell<SourceMap>>, ) { let q = ring.submission_queue(); let id = source_map.borrow_mut().add_source(source, Rc::clone(&q)); let mut queue = q.borrow_mut(); queue.submissions.push_back(UringDescriptor { args: descriptor, fd: source.raw(), user_data: id, }); } }
Each UringDescriptor contains all the information required to fill a SQE. For example, since invoking io_uring_prep_write requires providing a buffer to write data from, its corresponding UringOpDescriptor::Write requires providing a pointer and size for the buffer.
#![allow(unused)] fn main() { struct SleepableRing { ring: iou::IoUring, in_kernel: usize, submission_queue: ReactorQueue, name: &'static str, source_map: Rc<RefCell<SourceMap>>, } pub(crate) type ReactorQueue = Rc<RefCell<UringQueueState>>; pub(crate) struct UringQueueState { submissions: VecDeque<UringDescriptor>, cancellations: VecDeque<UringDescriptor>, } pub(crate) struct UringDescriptor { fd: RawFd, user_data: u64, args: UringOpDescriptor, } #[derive(Debug)] enum UringOpDescriptor { PollAdd(PollFlags), Write(*const u8, usize, u64), ... } }
Each UringDescriptor has a unique user_data field. This is the same user_data field on each SQE and is passed as-is from the SQE to the CQE. To generate a unique Id, the add_source method returns a new unique Id by incrementing a counter each time add_source is called:
#![allow(unused)] fn main() { impl SourceMap { ... fn add_source(&mut self, source: &Source, queue: ReactorQueue) -> u64 { let id = self.id; self.id += 1; self.map.insert(id, source.inner.clone()); id } }
Submitting the Events
Consuming the event is performed by the consume_submission_queue method, which calls consume_sqe_queue. It repeatedly calls prep_one_event to add a SQE entry on the io_uring's submission queue by calling prepare_sqe to allocate a new SQE and calling fill_sqe to fill in the necessary details.
If dispatch is true, it then calls submit_sqes which finally sends the SQEs to the kernel.
#![allow(unused)] fn main() { impl UringCommon for SleepableRing { fn consume_submission_queue(&mut self) -> io::Result<usize> { let q = self.submission_queue(); let mut queue = q.borrow_mut(); self.consume_sqe_queue(&mut queue.submissions, true) } fn consume_sqe_queue( &mut self, queue: &mut VecDeque<UringDescriptor>, mut dispatch: bool, ) -> io::Result<usize> { loop { match self.prep_one_event(queue) { None => { dispatch = true; break; } Some(true) => {} Some(false) => break, } } if dispatch { self.submit_sqes() } else { Ok(0) } } fn prep_one_event(&mut self, queue: &mut VecDeque<UringDescriptor>) -> Option<bool> { if queue.is_empty() { return Some(false); } if let Some(mut sqe) = self.ring.sq().prepare_sqe() { let op = queue.pop_front().unwrap(); // TODO: Allocator fill_sqe(&mut sqe, &op); Some(true) } else { None } } fn submit_sqes(&mut self) -> io::Result<usize> { let x = self.ring.submit_sqes()? as usize; self.in_kernel += x; Ok(x) } } fn fill_sqe(sqe: &mut iou::SQE<'_>, op: &UringDescriptor) { let mut user_data = op.user_data; unsafe { match op.args { UringOpDescriptor::PollAdd(flags) => { sqe.prep_poll_add(op.fd, flags); } ... } sqe.set_user_data(user_data); } } }
Step 3 - Processing the CQE
After adding a SQE to the io_uring's submission queue, the executor needs a way to detect when the I/O operation is completed and resume the task that is blocked.
Detecting when the I/O operation is completed is done by checking if there are new CQE entries on the io_uring instance’s completion queue. Resuming the task that is blocked is performed by calling wake() on the stored Waker in the Source.
API
Each Reactor has a wait API that the executor can use to check for new CQE entries and process the completed event. Here is its API:
#![allow(unused)] fn main() { pub(crate) fn wait(&self) -> () }
Implementation
The Reactor::wait API first calls consume_completion_queue to check if there are any new CQE entries. It then calls consume_submission_queue to submit SQE entries to the kernel as covered in the last page.
#![allow(unused)] fn main() { impl Reactor { ... pub(crate) fn wait(&self) { let mut main_ring = self.main_ring.borrow_mut(); main_ring.consume_completion_queue(); main_ring.consume_submission_queue().unwrap(); } } }
Here is the implementation of consume_completion_queue. It simply calls consume_one_event repeatedly until there are no more new CQE events. Consume_one_event simply invokes process_one_event.
#![allow(unused)] fn main() { pub(crate) trait UringCommon { ... fn consume_completion_queue(&mut self) -> usize { let mut completed: usize = 0; loop { if self.consume_one_event().is_none() { break; } else { } completed += 1; } completed } } impl UringCommon for SleepableRing { fn consume_one_event(&mut self) -> Option<bool> { let source_map = self.source_map.clone(); process_one_event(self.ring.peek_for_cqe(), source_map).map(|x| { self.in_kernel -= 1; x }) } } }
Here is the implementation for process_one_event:
#![allow(unused)] fn main() { fn process_one_event(cqe: Option<iou::CQE>, source_map: Rc<RefCell<SourceMap>>) -> Option<bool> { if let Some(value) = cqe { // No user data is `POLL_REMOVE` or `CANCEL`, we won't process. if value.user_data() == 0 { return Some(false); } let src = source_map.borrow_mut().consume_source(value.user_data()); let result = value.result(); let mut woke = false; let mut inner_source = src.borrow_mut(); inner_source.wakers.result = Some(result.map(|v| v as usize)); woke = inner_source.wakers.wake_waiters(); return Some(woke); } None } }
The method first retrieves the Source with the user_data on the CQE. Next, it wakes up the waiters stored on the Source. This resumes the tasks blocked by scheduling them back onto the executor.
The executor calls Reactor::wait on each iteration in the loop inside the run method via the poll_io method as shown below:
#![allow(unused)] fn main() { /// Runs the executor until the given future completes. pub fn run<T>(&self, future: impl Future<Output = T>) -> T { ... LOCAL_EX.set(self, || { ... loop { if let Poll::Ready(t) = join_handle.as_mut().poll(cx) { ... } // This would call Reactor::wait() self.parker .poll_io() .expect("Failed to poll io! This is actually pretty bad!"); ... } }) }